If you need to be the first one to know when any changes have been made on a website you can use this Python script. It compares the code of webpages every 5 minutes and tells you whether there are any differences have been made.
import requests
from bs4 import BeautifulSoup
import difflib
import time
from datetime import datetime
# target URL
url = "https://excelfiles.space/en/python-en/python-script-to-monitor-changes-on-a-webpage"
# act like a browser
headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36'}
PrevVersion = ""
FirstRun = True
while True:
# download the page
response = requests.get(url, headers=headers)
# parse the downloaded homepage
soup = BeautifulSoup(response.text, "lxml")
# remove all scripts and styles
for script in soup(["script", "style"]):
script.extract()
soup = soup.get_text()
# compare the page text to the previous version
if PrevVersion != soup:
# on the first run - just memorize the page
if FirstRun == True:
PrevVersion = soup
FirstRun = False
print ("Start Monitoring "+url+ ""+ str(datetime.now()))
else:
print ("Changes detected at: "+ str(datetime.now()))
OldPage = PrevVersion.splitlines()
NewPage = soup.splitlines()
# compare versions and highlight changes using difflib
d = difflib.Differ()
diff = d.compare(OldPage, NewPage)
out_text = "\n".join([ll.rstrip() for ll in '\n'.join(diff).splitlines() if ll.strip()])
print (out_text)
OldPage = NewPage
#print ('\n'.join(diff))
PrevVersion = soup
else:
print( "No Changes "+ str(datetime.now()))
time.sleep(300)
continue
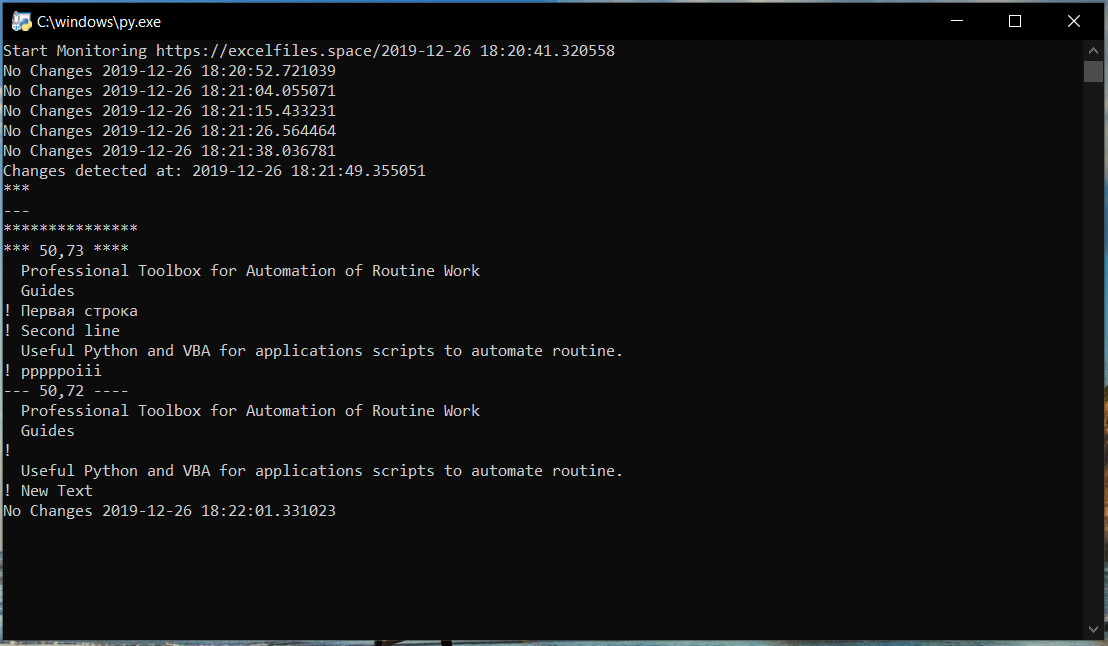
Result:

If we modify the script a little bit it can also show us what changed.
import requests
from bs4 import BeautifulSoup
import difflib
import time
from datetime import datetime
# target URL
url = "https://excelfiles.space/"
# act like a browser
headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36'}
PrevVersion = ""
FirstRun = True
while True:
# download the page
response = requests.get(url, headers=headers)
# parse the downloaded homepage
soup = BeautifulSoup(response.text, "lxml")
# remove all scripts and styles
for script in soup(["script", "style"]):
script.extract()
soup = soup.get_text()
# compare the page text to the previous version
if PrevVersion != soup:
# on the first run - just memorize the page
if FirstRun == True:
PrevVersion = soup
FirstRun = False
print ("Start Monitoring "+url+ ""+ str(datetime.now()))
else:
print ("Changes detected at: "+ str(datetime.now()))
OldPage = PrevVersion.splitlines()
NewPage = soup.splitlines()
# compare versions and highlight changes using difflib
#d = difflib.Differ()
#diff = d.compare(OldPage, NewPage)
diff = difflib.context_diff(OldPage,NewPage,n=10)
out_text = "\n".join([ll.rstrip() for ll in '\n'.join(diff).splitlines() if ll.strip()])
print (out_text)
OldPage = NewPage
#print ('\n'.join(diff))
PrevVersion = soup
else:
print( "No Changes "+ str(datetime.now()))
time.sleep(10)
continueOutput: